
Inspired by the course led by Hamel Husain and Shreya Shankar. The stories and examples are mine.
The Whole Loop in One Picture
Analyze → Measure → Improve
- Analyze: Look at what your AI did, spot what went wrong, name it.
- Measure: Count how often each type of problem shows up.
- Improve: Fix the biggest issues, then repeat.
The rest of this post walks through step 1 in detail and shows how it connects to the other two steps.
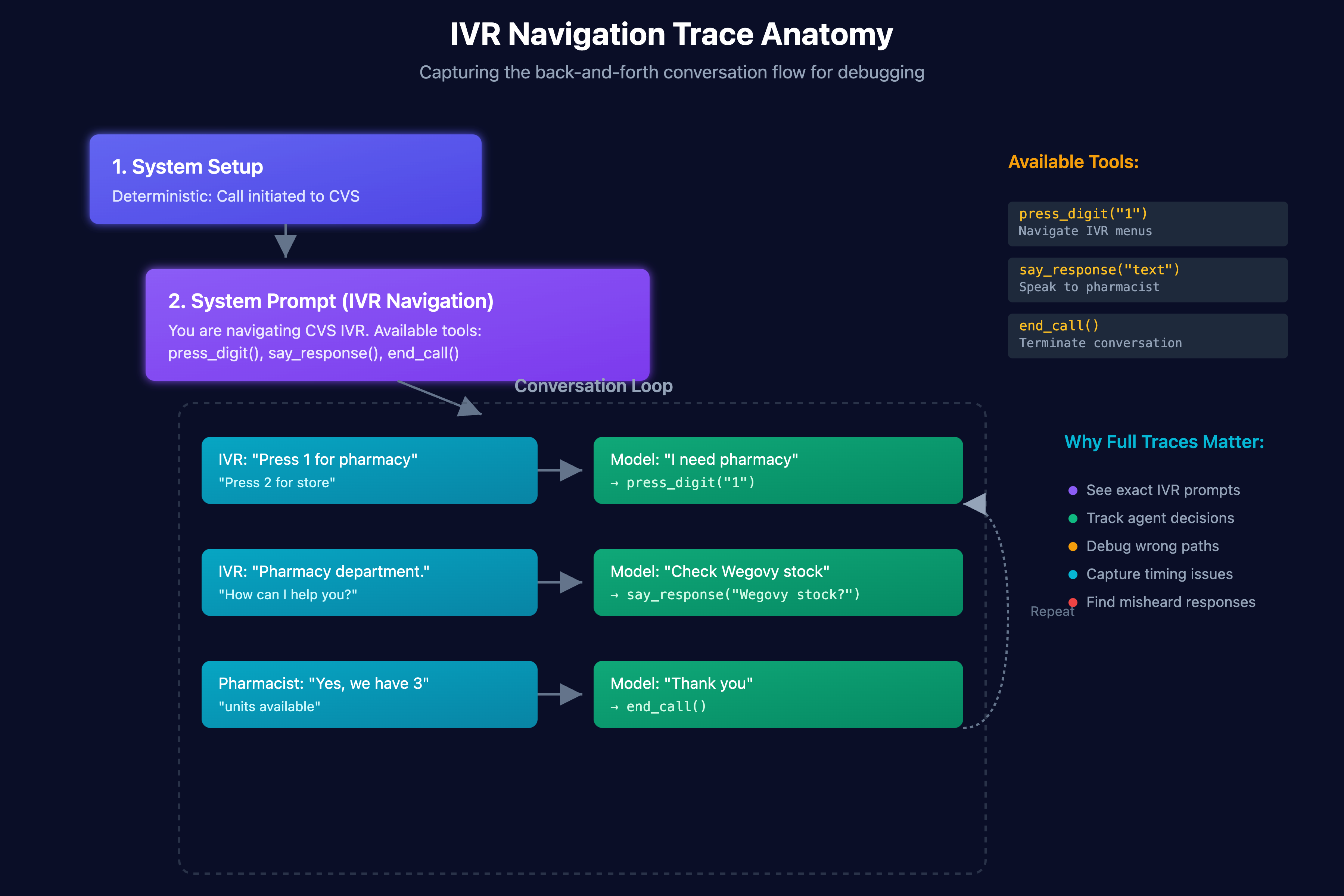
Step 1. Capture Complete Traces
Plain English: Save everything that happened in each conversation with the AI so you can replay it later. Tools like langsmith or brainstrust can be good for this, but vibe coding your own dashboards that interface with the backend systems the agent is built around is the best method.
 Click to zoom
Click to zoom
What a trace should include
Example (mine): While building an agent that called pharmacies for Novo Nordisk, one call “confirmed” a prescription transfer but the pharmacy never received it. Because our trace stored the IVR steps, the DTMF keys pressed, and the tool outputs, we saw the agent pressed 0 instead of 1 and got routed to the wrong menu. Without the full trace we would've been helpless to fix it.
Common mistakes: Logging only the final answer, storing tool outputs in a different system so reviewers cannot see them, and losing the system prompt or intermediate messages.
Have the right tooling
Step 2. Get About 100 Diverse, Realistic Conversations
If you have production data, use it (with proper privacy). If you don't create synthetic conversations carefully.
Start with hypotheses & stress tests
- Use your product (or watch real users) dozens of times adversarially: try the weird, annoying, or expensive cases. Note where it breaks.
- Those hypotheses guide which dimensions you sample. “Realistic + high‑signal” beats “random + bland.”
- Don't just ask an LLM for sample queries. It will happily generate 50 near-duplicates.
- Brainstorm too many dimensions first (30–50). Then keep the 3–5 that actually change behavior.
Dimensions drive diversity
A dimension is an aspect of the request that meaningfully changes how your agent should behave. There can be many. The three below are examples, not a checklist. Your set depends on your product. Put your product hat on and empathize with your users. If you can't list the key dimensions, that's a loud signal you don't understand who you're building for or what they need.
Novo Nordisk pharmacy-calling agent (my project):
- Intent: check stock, transfer a prescription, fill a prescription, verify insurance info
- Persona: pharmacist vs pharmacy technician (techs often lack authority or information and need to transfer us)
- Complexity / Channel noise: clear call vs bad audio, background noise, garbled transcription, asking for data the agent does not have
Other products will have different axes: language, jurisdiction, urgency, safety risk, etc. Brainstorm many, then keep the 3 to 5 that change behavior the most.
How to create useful synthetic data
- List values for each chosen dimension (at least three per dimension).
- Combine them into tuples (Intent x Persona x Complexity, for example).
- Turn each tuple into a realistic prompt or call scenario.
- Run the bot and log the traces.
Why ~100? The goal is to continue until you stop seeing brand new failure types. That plateau is called theoretical saturation. Stopping early usually means you missed costly edge cases.
Step 3. Open Coding: First Pass Notes
Read each trace and write one short note about what went wrong. Keep it fast.
Rules
- Stop at the first upstream failure. Once it goes wrong, everything downstream is noise.
- Use concrete language that you can later group. You're building raw material for a taxonomy.
- Don't fix it yet! Now is the time to label, not fix.
- Don’t automate this (yet). Even GPT‑4.1 missed obvious errors in class; manual review is the "secret weapon."
- User mistakes ≠ model failures. Only note typos/garble if the model mishandled them.
- Logging glitches are their own issue. Mark and remove/fix partial traces rather than labeling them as model errors.
Novo Nordisk examples:
- "Did not pass IVR. Pressed 0, needed to press 1. Routed to general store, never reached pharmacy"
- "Got stuck in IVR loop, no escape command triggered"
- "Misheard Rx number due to noise, asked for refill on wrong medication"
- "Pharmacist asked for information we do not have (patient DOB) and conversation stalled"
Bad notes
- Anything vague: "Confusing conversation", "Improve prompt", "Weird"
- Typos from the user. Ignore them unless the model mishandled the typo in a meaningful way. Remember you will build categories from these notes. If a note is fuzzy, you hurt yourself later.
Aim for 10 to 30 seconds per trace once you find your rhythm.
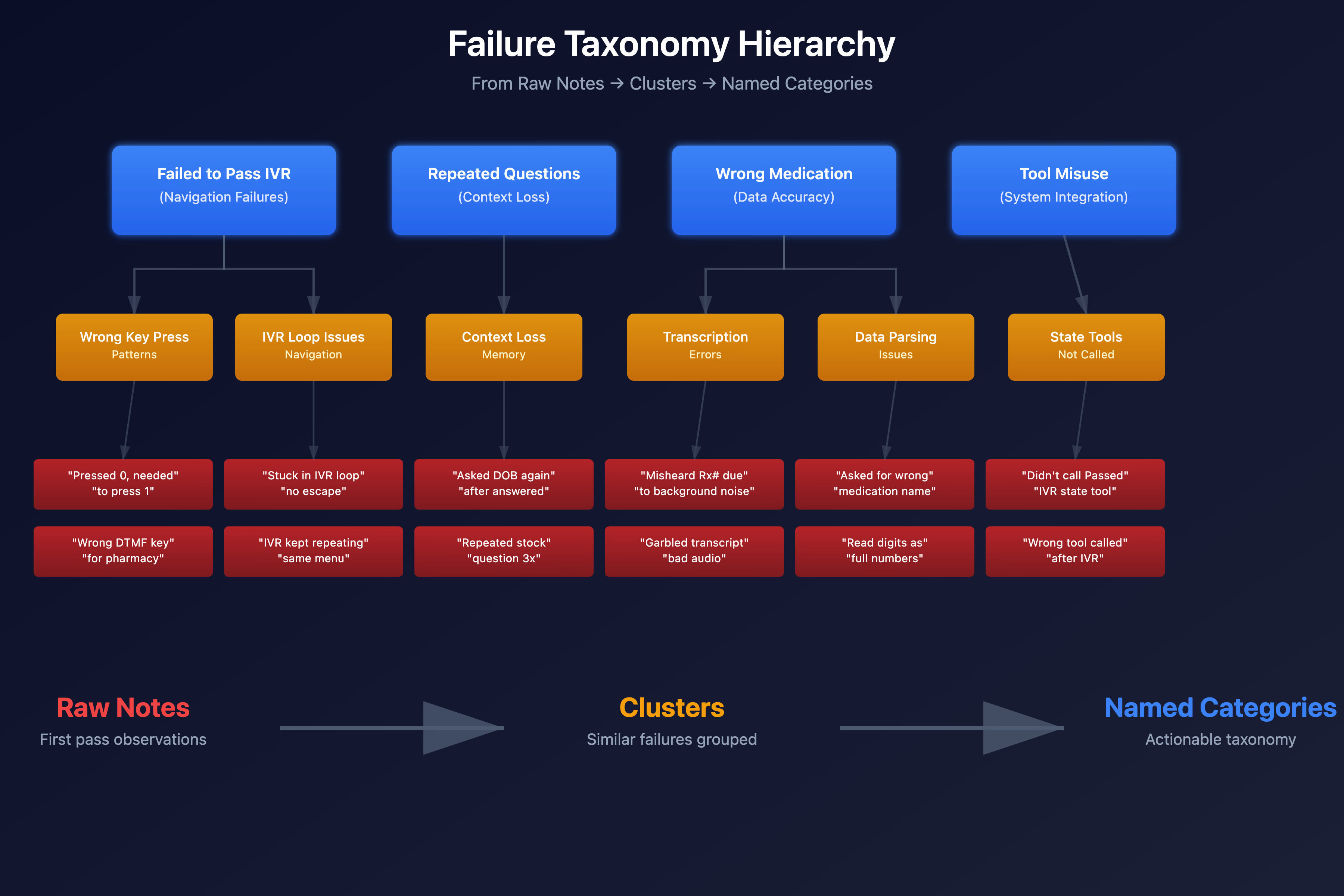
Step 4. Axial Coding: Turn Notes Into Categories
 Click to zoom
Click to zoom
This is where you build the taxonomy from your open codes. Group similar failures and name the buckets clearly.
How to do it
- Dump all notes into a sheet or whiteboard
- Cluster by similarity
- Name each cluster so it suggests an action later ("Reschedule tool missing" > "Scheduling weirdness").
From taxonomy to evaluators
Right after you lock your buckets, sketch how you’ll measure them automatically (regex checks, tool-call audits, LLM graders, heuristics). Axial coding should hand a spec to whoever builds evaluators.
Novo Nordisk buckets we ended with:
- Failed to pass IVR (wrong key, wrong path, stuck loop)
- Repeated a question after the pharmacist already answered
- Asked for the wrong medication or misread numbers/letters
- Spoke numbers in a way humans could not parse (read full digits instead of one at a time)
- Used the wrong tool or no tool at all (Finished IVR and didn't call the Passed IVR state tool to change prompts to the pharmacist specific one)
You're going to have a long tail of issues, and that's ok! A few categories usually explain most pain.
Step 5. Measure What Matters
Now count. How many traces fall in each bucket? How severe are they?
Simple spreadsheet columns
- Trace ID
- Failure category
- Severity (1–3) and business impact (cost/churn/risk score)
- Frequency counter (auto-computed)
- Short note / exemplar quote
Prioritize by Severity × Frequency (and cost if you can estimate it).
This gives you a heat map for prioritization.
Step 5½. Automate What You Can Evaluate
Before fixing, make the taxonomy actionable and automate deterministically whenever possible:
- Prefer rules first: regexes, schema/format checks, and tool‑call validations wired into CI. (When we did Novo Nordisk, I used LLM graders, but simple regex + tool‑call checks in CI would have caught many issues just as effectively.)
- Use LLM graders only when you can't easily write a deterministic check, and always spot‑check them, they have blind spots that aren't always obvious.
- Add all evaluators to CI or nightly jobs so regressions pop immediately.
Step 6. Improve The System
With priorities in hand, fix systematically.
Novo Nordisk fixes:
- Built separate IVR prompt snippets and key maps for each major chain (CVS, Walgreens, Rite Aid). We charted every branch so the agent knew exactly what to press and say. Skipping IVR was expensive, so this paid off fast.
- Added explicit wording rules for pharmacists: read Rx and phone numbers one digit and one letter at a time.
- Created intent checks for "transfer", "stock check", "fill" so the agent asked for the right thing up front.
- Added a fallback: if agent requests info we do not have, immediately ask to be transferred to the pharmacist or to speak with someone who can access it.
Then we reran the loop, re-measured, and kept iterating.
Quick Reference Checklist
- Log full traces in one place
- List product-specific dimensions. If you cannot, revisit your user understanding
- Generate about 100 realistic conversations across those dimensions
- Open code each trace with one clear, concrete failure note
- Cluster notes into a taxonomy (axial coding)
- Measure frequency and severity
- Fix top issues, add evaluators, loop back
Stick this on your wall. It works.
Credit Where It’s Due
This process comes from the course I'm taking with Hamel Husain and Shreya Shankar. They deserve the credit for the framework. I did the work on Novo before taking their course, and was delighted that some of the things I developed to aid in the eval process were suggested by them. Still, their process is more refined than mine was, and so this also functions as a post mortem for me on how that project could have been improved.
If you want help applying this to your own AI product, just reach out!
Ready to Build Production AI Agents?
Let's discuss how AI agents can transform your business operations
Book a Strategy Call